想要Kafka好用,你就得知道这些大数据服务工具
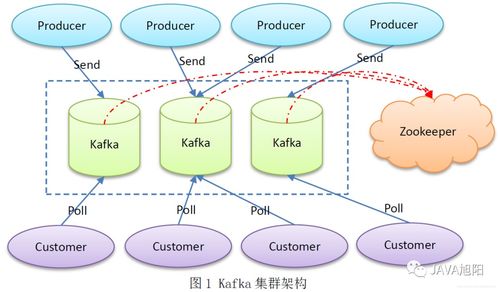
在大数据生态系统中,Apache Kafka 凭借其高吞吐、低延迟、可扩展性及持久化特性,已成为实时数据流处理的核心组件。仅仅部署 Kafka 集群并不意味着就能高效、便捷地使用它。要让 Kafka 真正“好用”,充分发挥其威力,离不开一系列配套的大数据服务工具。这些工具覆盖了集群管理、监控、数据处理、开发调试和安全等关键环节,共同构成了一个健壮、可观测、易运维的数据流平台。
一、 集群管理与运维工具
- Kafka Manager / CMAK: 这是由 Yahoo 开源(后更名为 CMAK)的经典 Web UI 工具。它提供了直观的界面来管理多个 Kafka 集群,可以轻松查看集群状态、Topic 列表、消费者组偏移量、分区分布,并进行 Topic 创建、分区扩缩容、副本重分配等关键操作。对于运维人员来说,它是降低管理复杂性的利器。
- Confluent Control Center: 作为 Confluent 平台(Kafka 的商业发行版)的核心组件,它提供了企业级的 GUI 管理界面。其功能远超开源管理器,集成了强大的监控告警、数据流 lineage 追踪、主题和客户端配置管理,以及对 Kafka Connect 和 ksqlDB 的可视化支持,是构建生产级数据流平台的重要选择。
- kube-prometheus-stack 与 Strimzi: 在 Kubernetes 环境中,Strimzi 项目提供了在 K8s 上部署和管理 Kafka 集群的 Operator,极大地简化了云原生环境下的生命周期管理。结合 kube-prometheus-stack(包含 Prometheus 和 Grafana),可以实现对 Kafka 集群从基础设施到 JVM 指标的自动化、全方位监控与告警。
二、 监控与可观测性工具
- Prometheus + Grafana: 这是监控领域的黄金组合。通过使用 JMX Exporter 暴露 Kafka Broker、ZooKeeper 以及客户端(如 Connect、Streams)的 JMX 指标,Prometheus 可以抓取并存储这些时间序列数据。Grafana 则用于构建丰富的监控仪表盘,可视化关键指标,如字节流入/出速率、请求队列长度、网络处理器空闲率、副本滞后数等,帮助快速定位性能瓶颈和故障。
- Burrow 或 Kafka Eagle: 监控消费者滞后(Consumer Lag)是保障数据实时性的关键。Burrow 是 LinkedIn 开源的一款独立的消费者滞后评估工具,它不依赖消费者组自身的偏移量提交,而是提供了一种更可靠的评估和告警机制。Kafka Eagle 则是一款国产的集监控、管理和告警于一体的 Web 工具,对消费者滞后的监控是其亮点之一。
- ELK Stack (Elasticsearch, Logstash, Kibana) 或 Loki: 集中化的日志收集与分析同样不可或缺。将 Kafka Broker、应用客户端以及相关组件的日志统一收集到 Elasticsearch 或 Grafana Loki 中,通过 Kibana 或 Grafana 进行查询和可视化,可以极大地提升排错效率,尤其是在分析分布式系统问题时。
三、 数据处理与开发工具
- Kafka Connect: 这是 Kafka 生态中用于与外部系统进行可扩展、可靠数据集成(ETL)的框架。它提供了丰富的预构建连接器(Connectors),可以轻松地将数据从数据库(如 MySQL、PostgreSQL)、消息队列、云存储等导入到 Kafka Topic,或将 Kafka 数据导出到各种数据仓库(如 HDFS、S3、Elasticsearch)和分析系统。用好 Connect 能省去大量自定义数据同步代码的工作。
- ksqlDB: 这是 Confluent 推出的基于 Kafka 的流式 SQL 引擎。它允许开发者使用熟悉的 SQL 语句对 Kafka 中的数据流进行实时处理,包括过滤、转换、聚合和连接,而无需编写复杂的 Java/Scala 流处理代码。对于需要快速构建实时报表、异常检测或数据清洗管道的场景,ksqlDB 极大地降低了开发门槛。
- Apache Flink / Spark Streaming: 对于更复杂的有状态流处理需求(如窗口计算、复杂事件处理CEP),Flink 和 Spark Streaming 是 Kafka 上游的强大处理引擎。它们能从 Kafka 高效消费数据,进行高级计算后再写回 Kafka 或其他存储,构建端到端的实时数据管道。
四、 客户端与调试工具
- kcat (原 kafkacat): 这是一个命令行工具,堪称 Kafka 的“瑞士军刀”。它可以作为生产者、消费者或元数据查询工具,用于快速测试 Topic、调试消息格式、检查分区数据等,比使用原生命令行脚本更灵活、高效。
- Confluent Kafka Clients / librdkafka: 一个成熟、高性能的客户端库是应用开发的基础。除了官方 Java 客户端,Confluent 提供的各语言客户端(基于 librdkafka C 库)在功能和性能上都有良好保证,支持高级特性如事务、精确一次语义(EOS)等。
- UI for Apache Kafka: 这是一款轻量级的桌面客户端工具,提供了可视化的界面来浏览集群、查看消息内容(支持多种格式解析)、管理消费者组等,非常适合开发者在本地开发和调试时使用。
五、 安全与治理工具
- Confluent Schema Registry: 在数据格式演进中保证前后兼容性至关重要。Schema Registry 提供了中心化的 Avro、Protobuf 或 JSON Schema 服务,管理生产者与消费者之间数据格式的契约,确保不同版本服务间的平滑协作,是实现数据治理和减少“数据沼泽”的关键组件。
- Apache Ranger 或 Confluent RBAC: 在生产环境中,Kafka 集群的安全访问控制必不可少。Apache Ranger 可以为 Kafka 提供细粒度的权限策略管理(Topic 级别的读写权限)。Confluent 平台则提供了基于角色的访问控制(RBAC),并与 Schema Registry、Connect 等组件深度集成,提供统一的安全管理。
让 Kafka 从“能用”到“好用”,关键在于构建一个完整的工具生态。从便捷的集群管理(CMAK、Control Center)和全方位的监控(Prometheus+Grafana),到高效的数据集成(Kafka Connect)与处理(ksqlDB、Flink),再到顺手的开发调试(kcat、UI工具)和必不可少的安全治理(Schema Registry、Ranger),这些工具共同作用,将 Kafka 从一个强大的消息引擎,提升为一个稳定、高效、易运维的企业级实时数据流中枢。根据自身的技术栈、团队规模和业务需求,有选择地引入和整合这些工具,是驾驭好 Kafka 这头“数据巨兽”的必由之路。
如若转载,请注明出处:http://www.yumuyun.com/product/4.html
更新时间:2026-04-29 09:02:20